
Q-Learning, a cornerstone concept in the world of reinforcement learning (RL), can be both intriguing and complex. But don’t worry, we’ll break it down together! In this post, we’ll explore the foundations, mechanisms, and applications of Q-Learning. So, whether you’re an aspiring AI enthusiast, a student, or just curious about how machines learn to make decisions, you’re in the right place.
Table of Contents
- Introduction to Q-Learning
- The Q-Learning Algorithm: How It Works
- Understanding the Q-Table
- Exploration vs. Exploitation Dilemma
- Real-World Applications of Q-Learning
- Challenges and Limitations
1. Introduction to Q-Learning
Q-Learning is a model-free reinforcement learning algorithm. It’s used to find the best action to take given the current state. It’s like teaching a child to navigate a maze; they try different paths (actions) from their current location (state) and remember the paths that led to rewards.
Key Concepts:
- Agent: The learner or decision-maker.
- Environment: What the agent interacts with.
- States: Different situations or positions in the environment.
- Actions: What the agent can do.
- Rewards: Feedback from the environment.
2. The Q-Learning Algorithm: How It Works
At its core, Q-Learning seeks to learn a policy, dictating the best action to take in a given state. It does this through a process called ‘trial and error’, where the agent explores the environment, makes decisions, and learns from the outcomes.
The Q-Learning Formula:
-
α (Alpha): Learning rate.
-
γ (Gamma): Discount factor.
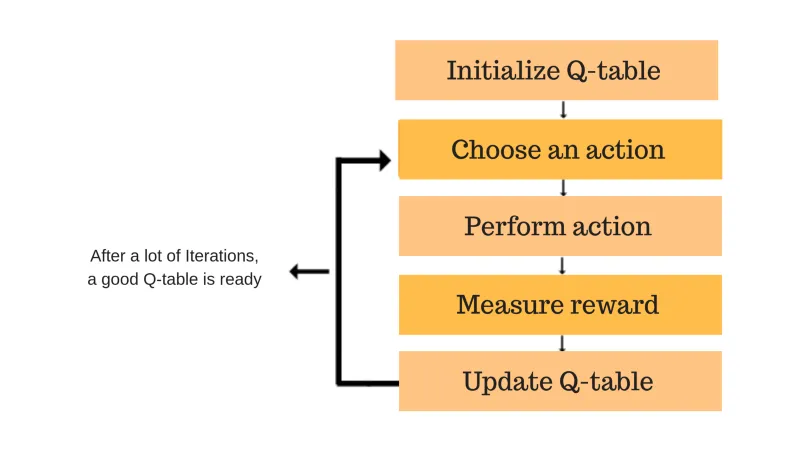
Steps Involved:
- Initialize the Q-values: Q-values are initialized to arbitrary values.
- Choose an action: Based on the current state and Q-values.
- Perform the action: Observe the reward and new state.
- Update the Q-value: For the state-action pair based on the formula.
3. Understanding the Q-Table
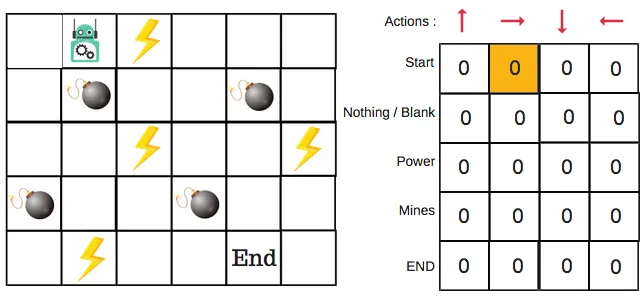
The Q-table is the brain of Q-Learning. It’s a matrix where rows represent states, and columns represent actions. The values in the table are the Q-values, which represent the ‘quality’ of a specific action taken in a specific state.
How the Q-Table is Updated:
The Q-table gets updated as the agent explores the environment, providing a reference for the agent to decide the best action to take in each state.
4. Exploration vs. Exploitation Dilemma
A crucial aspect of Q-Learning is balancing exploration (trying new things) and exploitation (using known information). This balance is vital for effectively learning the optimal policy.
Strategies to Balance Exploration and Exploitation:
- Epsilon-Greedy Strategy: The agent explores randomly with a probability of ε and exploits known information with a probability of 1-ε.
- Decay in Exploration: Reducing ε over time to shift from exploration to exploitation.
5. Real-World Applications of Q-Learning
Q-Learning isn’t just theoretical; it has practical applications, such as:
- Robotics: For autonomous navigation.
- Gaming: Developing AI that can play games.
- Finance: For portfolio management and algorithmic trading.
6. Challenges and Limitations
While powerful, Q-Learning has its limitations:
-
Scalability: It struggles with large state and action spaces, making it less suitable for high-dimensional or continuous environments.
-
Overestimation of Q-values: It tends to overestimate action values, which can lead to suboptimal decisions. Techniques like Double Q-Learning are used to address this issue and enhance reliability.


